Datenintegrität
Manfred Rätzmann
RÄTZMANN GmbH, Claudiusstraße 3, 10557 Berlin
m.raetzmann@raetzmann-gmbh.de
Dieser Artikel ist
ursprünglich im „Fuchs“, der Zeitschrift der deutschsprachigen FoxPro User
Group (dFPUG) erschienen. Alle Codebeispiele etc. beziehen sich also auf den
Umgang mit der Datenbank von Microsoft Visual FoxPro (VFP). Ich denke aber,
dass einige der angesprochenen Aspekte von Datenintegrität auch für Entwickler
interessant sind, die mit anderen Datenbanken arbeiten.
Datenintegrität
Die Integrität der Daten
sollte für jeden Datenmodellbauer das oberste Gebot sein. Performance,
Wartbarkeit und Wiederverwendbarkeit der Datenstrukturen müssen dabei
zurückstehen. Denn niemandem ist mit einer superschnellen Applikation gedient,
die leicht zu warten ist und deren Ergebnisse man vielfach weiterverwenden
kann, wenn auf eben diese Ergebnisse kein Verlass ist. Leider hat aber die
Sicherstellung der Datenintegrität durchaus Auswirkungen auf die Performance
der Datenbank. Je mehr Regeln überprüft werden müssen, desto länger wird das
Einfügen, Löschen oder Ändern eines Datensatzes dauern. Lassen Sie sich aber
nicht verleiten, zu Gunsten der Performance auf Integritätsprüfungen zu
verzichten. Vor allem dann nicht, wenn auch andere Programme in Ihrer Datenbank
Sätze speichern oder verändern können. Nutzen Sie die in diesem Artikel
erläuterten Techniken zur Sicherstellung der Datenintegrität einfach, um besser
schlafen zu können.
Datenintegrität hat drei
Aspekte:
1.
Integrität der Werte
(Value Integrity VI)
2.
Integrität der Referenzen
(Referential Integrity RI)
3.
Einhaltung der
Geschäftsregeln (Business Rules BR)
Integrität der Werte
Die Integrität der Werte
wird durch Feldvalidierung und Satzvalidierung sichergestellt. Darüber hinaus
ist die Integrität von Werten auch bei Abhängigkeiten von Datensätzen
untereinander betroffen. In einem Artikeldatensatz könnte zum Beispiel der
Preis des Artikels hinterlegt sein. Außerdem enthält der Artikeldatensatz eine
Mengeneinheit, die angibt, auf welche Einheit sich der Preis bezieht. Eine
Regel zur Aufrechterhaltung der Werteintegrität muss nun sicherstellen, dass
die Mengeneinheit nicht gelöscht wird, da sonst der Preis seinen Bezug
verliert. Solche Regeln werden wir weiter unten zusammen mit der referentiellen
Integrität noch näher beleuchten.
Feldvalidierung
Regeln zur
Feldvalidierung prüfen die Gültigkeit eines einzelnen Feldes. Typische
Beispiele sind Felder vom Typ Datum, deren Werte nicht vor dem aktuellen
Tagesdatum liegen dürfen oder Felder mit Preisen, die nicht kleiner Null sein
dürfen. Wenn eine Feldvalidierungsregel verletzt wird, verhindert die
Datenbank, dass der Feldwert gespeichert wird.
In VFP können Sie eine Regel zur Feldvalidierung in
Form eines Ausdrucks hinterlegen. Der Ausdruck gibt an, wie der im Tabellenfeld
eingetragene Wert auf Gültigkeit überprüft werden soll und muss einen logischen
Wert .T. oder .F. zurückliefern. Wenn ein Tabellenfeld zum Beispiel nur
Datumswerte enthalten soll, die größer oder gleich dem aktuellen Systemdatum
sind, könnten Sie dies über den Ausdruck <Feldname> >= date() abprüfen. Statt <Feldname> muss dabei
natürlich der aktuelle Feldname angegeben werden. Komplexere Abprüfungen können
auch in eigenen Funktionen durchgeführt werden, die bei Gültigkeit des
abzuprüfenden Wertes ein .T. zurückliefern und ein .F., wenn der Wert im
Tabellenfeld nicht gültig ist. Solche Funktionen werden am besten direkt in der
Datenbank gespeichert. Gespeicherte Funktionen oder Prozeduren werden beim
Öffnen der Datenbank automatisch in den Speicher geladen. Sie sollten sich
deshalb auf Funktionen beschränken, die immer dann verfügbar sein müssen, wenn
die Datenbank-Struktur oder die in der Datenbank gespeicherten Daten verändert
werden. Dies trifft generell auf die Funktionen zu, die von den Ausdrücken
aufgerufen werden, die die Gültigkeitsregeln für Tabellenfelder und
Tabellensätze beschreiben. Die Funktionen, die von den UPDATE-, INSERT- und DELETE- Triggern (siehe
weiter unten) aufgerufen werden, gehören ebenfalls als gespeicherte Prozeduren
in die Datenbank.
Die Gültigkeitsregel wird sofort überprüft, sobald der Anwender das mit dem
Tabellenfeld verbundene Eingabefeld verlassen will. Dies ist unabhängig von der
Art der Pufferung und gilt sowohl für Eingabemasken als auch für den BROWSE
Befehl. Durch das Festlegen von Gültigkeitsregeln auf Feld oder Satzebene kann
damit auch verhindert werden, dass über BROWSE oder durch andere Programme, die
über ODBC auf die Tabelle zugreifen, nicht gültige Werte in ein Tabellenfeld
geschrieben werden.
Wenn Sie eine
Gültigkeitsregel für ein Feld später nachtragen, so sollten alle bereits in der
Tabelle gespeicherten Sätze dieser Regel entsprechen. Visual FoxPro prüft dies
auf Wunsch vor dem Speichern Ihrer neuen Regel ab und weigert sich, diese Regel
zu speichern, wenn die Tabelle bereits Sätze enthält, die die Regel verletzen.
Wenn Sie auf diese Prüfung verzichten müssen Sie selber sicherstellen, dass
alle bereits gespeicherten Sätze der neuen Regel entsprechen.
Ein Tipp für xCase
Anwender: Mit @FIELD können Sie einen Platzhalter für den Feldnamen bereits in
der Feldvalidierungsregel der xCase Domain hinterlegen. Das obige Beispiel
würde dann als Domaindefinition @FIELD >= date() lauten.
Terminprüfungen haben
ihre Tücken, vor allem, wenn Sie mit datetime() arbeiten. Die Regel <Feldname>
>= datetime() und der
Default-Wert datetime() für ein Feld können bedeuten, dass der Satz schon beim ersten Speichern
abgelehnt wird. Aber auch, wenn der Anwender einen Satz später wieder aufruft,
versehentlich im Terminfeld etwas ändert kommt es zu Problemen. Selbst wenn er
oder sie den Wert wieder eingibt, der vorher in diesem Feld stand, wird der
Satz abgelehnt, da ja gegen date() oder datetime() abgeprüft wird. Was der Designer wollte, war eigentlich etwas anderes: Es
sollten keine Sätze angelegt werden können, deren Terminangabe bereits in der
Vergangenheit liegt. Irgendwann liegt aber jeder Termin in der Vergangenheit.
Besser ist es also, nicht gegen date() oder datetime() abzuprüfen, sondern gegen das Erstellungsdatum das Satzes. Dazu braucht man
ein weiteres, nicht änderbares Feld, das als Default-Wert beim Anlegen des
Satzes datetime() aufnimmt.
Ein solches Feld für den
Erstellungszeitpunkt des Satzes ist ein gutes Beispiel für Felder, die einmal
beschrieben und danach nicht mehr geändert werden sollten. Auch dazu kann die
Feldvalidierungsregel eingesetzt werden. In diesem Fall bietet sich der Aufruf
einer kleinen Funktion DontChange() aus den Stored
Procedures an:
function DontChange
lParameter cFieldName
* bei neu eingefügten Sätzen liefert oldval()ein .NULL.
zurück
* die IF-Bedingung ist dann FALSE
* deshalb brauchen wir isnull() nicht gesondert zu
überprüfen
if oldval(cFieldname) <> evaluate(cFieldName)
return .F.
endif
endfunc
Für das Feld RecDate (als
Beispiel) wird dann DontChange(‘RecDate‘) als Feldvalidierungsregel eingetragen.
Satzvalidierung
Regeln zur
Satzvalidierung prüfen die Gültigkeit eines Datensatzes. Auch hier wird das
Speichern eines ungültigen Satzes durch die Datenbank verhindert.
Satzvalidierung ist immer dann wichtig, wenn die gültigen Werte für Felder des
Datensatzes von einander abhängen. Ein Beispiel wäre eine Auftragsposition, bei
der sich Rabatt und Mindermengenzuschlag gegenseitig ausschließen. Das lässt
sich auf Feldebene schlecht abprüfen, da der Anwender ja jederzeit noch den
einen oder anderen Wert eintragen könnte.
Die Abprüfung, ob alle im
Satz vorhandenen Fremdschlüssel auf einen gültigen Satz in der verknüpften
Tabelle verweisen, ist nicht Sache der Satzvalidierung sondern der Prüfung auf
referentielle Integrität, die weiter unten behandelt wird.
Pufferung beachten
Visual FoxPro führt die
Prüfung der Gültigkeitsregel auf Satzebene direkt vor dem Speichern aus.
Hierbei ist jetzt aber die Frage der Pufferung wichtig. Wenn Sie, wie früher
unter FoxPro 2.x, mit einer ungepufferten Tabelle arbeiten, wird die
Gültigkeitsregel auf Satzebene sofort nach einer Änderung an einem Tabellenfeld
überprüft. Dies führt unter Umständen zu einem Konflikt, da eine solche Regel
ja voneinander abhängige Felder überprüft, die alle erst mit den richtigen
Werten versorgt werden müssen. Ein satzweises Puffern ist also in den meisten
Fällen erforderlich, wenn Sie eine Gültigkeitsregel auf Satzebene verwenden
wollen.
Ausdrücke oder Prozeduren?
Verwenden Sie zur Feld-
und Satzvalidierung VFP Ausdrücke an Stelle gespeicherter Prozeduren, wenn
möglich. Der Aufruf einer gespeicherten Prozedur dauert länger als die
Auswertung eines Ausdrucks, deshalb sind Tabellen, die ihre Validierungen über
Ausdrücke erledigen im allgemeinen performanter als Tabellen, die zur
Validierung Stored Procedures aufrufen. Wenn bei der Satzvalidierung allerdings
umfangreichere Geschäftsregeln abgeprüft werden müssen, werden diese als Stored Procedure
programmiert.
Satzvalidierung und Geschäftsregeln (Business-Rules)
Das, was bei der
Satzvalidierung überprüft wird, sind häufig die sogenannten Geschäftsregeln
oder Business-Rules. Geschäftsregeln besagen, welche Vorgehensweisen und Restriktionen der
ordnungsgemäße und gewünschte Geschäftsablauf dem Umgang mit der Datenbasis
auferlegt. Eine typische Geschäftsregel sagt zum Beispiel, dass ein Artikel
nicht unter einem festgelegten Mindestpreis verkauft werden darf. Die
Validierung von Auftragspositionssätzen könnte dies abprüfen. (Wenn bei der
Ermittlung des Verkaufspreises auch Rabattsatz und eventuell folgende Rabatte
auf Zwischensummen eine Rolle spielen, ist das als Feldvalidierung nicht zu
machen.) Dazu muss in der Validierungsprozedur auf andere Tabellen oder auch
auf andere Sätze der gleichen Tabelle zugegriffen werden. Das ist ohne weiteres
möglich. Beachten Sie dabei aber, dass der Satzzeiger im aktuellen
Arbeitsbereich nicht verschoben werden darf. Wenn Sie auf andere Sätze der
gleichen Tabelle zugreifen müssen, öffnen Sie die Tabelle zwischenzeitlich
unter einem anderen Alias noch einmal.
Eine andere typische
Geschäftsregel ist, dass ein Kunde nicht gelöscht werden darf, solange noch
offene Posten dieses Kunden vorliegen. Solche Regeln können bei der
Satzvalidierung nicht geprüft werden, da diese beim Löschen eines Satzes nicht
durchgeführt wird. (Beim Recall eines Satzes wird die Satzvalidierung jedoch
durchgeführt.) Wie Prozeduren solcher Geschäftsregeln über die Trigger aufgerufen werden,
sehen wir weiter unten.
Fehlende Daten ergänzen
Die Satzvalidierung kann
auch dazu verwendet werden, abgeleitete Felder des Satzes mit Werten zu füllen.
So könnten Sie zum Beispiel den Zeitpunkt der letzten Änderung automatisch über
eine an die Satzvalidierung geknüpfte StoredProcedure fortschreiben.
function SetLastUpd
lParameter cFieldname
* wurde ein Parameter übergeben?
assert type("cFieldName") = "C"
* zeigt der Parameter auf ein Feld?
assert
!inlist(type(cFieldName),"U","G")
replace &cFieldname with datetime()
endfunc
Ein solches Ergänzen von
Werten im bearbeiteten Satz ist aus dem Update-Trigger (siehe unten) nicht möglich. Vermeiden Sie aber
das Ergänzen von Werten in anderen Tabellen oder Sätzen der gleichen Tabelle
aus der Satzvalidierung heraus. Der Grund ist einfach der, dass der Update-
oder Insert-Trigger erst nach der Satzvalidierung gefeuert wird. Und dieser Trigger entscheidet
darüber, ob der Satz überhaupt gespeichert wird. Wenn Sie in der
Satzvalidierung bereits Daten in anderen Sätzen geändert haben, könnte das also
etwas voreilig gewesen sein.
Referentielle Integrität (RI)
Ein Datensatz kann
Verweise auf andere Datensätze enthalten. Eine übliche Aufteilung ist es zum
Beispiel, Adressen von Kunden, Lieferanten, Vertretern und Geschäftsfreunden in
einer zentralen Adresstabelle zusammen zu fassen. Weitere Daten, die zu Kunden
gespeichert werden sollen, bilden dann eine eigene Kundentabelle. Jeder
Datensatz der Kundendatei enthält dabei einen Verweis auf einen
Adressdatensatz. Die Regeln, die die referentielle Integrität aufrecht erhalten
sollen, betreffen Fragen wie: Was muss mit den Verweisen auf einen Datensatz passieren, wenn dieser Datensatz
gelöscht wird?
Im folgenden benutze ich
das Entity-Relationship (ER) Modeling Tool xCase um die Relationen und Regeln festzulegen, die die referentielle
Integrität sicherstellen sollen. Der Grund ist einfach der, dass mit dem VFP
Database Designer und dem RI Assistenten nicht alle Regeln darstellbar sind,
die man bei komplexeren Datenstrukturen braucht.
![]()
Dieses ER Diagramm
beschreibt eine Datenstruktur, in der eine Adresse zu genau einem oder keinem
Kunden gehört. Einem Kunden können Null, Eine oder mehrere Rechnungen
zugeordnet sein. Eine Rechnung besteht aus mindestens einer Position.
Welche Regeln müssen dann
für Insert,
Update und Delete eines Kundensatzes gelten?
1.
Insert: R = RESTRICT
Wenn ein neuer Kundendatensatz angelegt wird, muss dieser einen Verweis auf
einen gültigen Adresssatz enthalten. Damit wäre den RI-Regeln Genüge getan,
nicht aber der Forderung, dass ein Adressdatensatz nur zu einem Kunden – also
nicht zu zwei unterschiedlichen Kunden – gehören darf. Diese Forderung ist eine
Geschäftsregel, die zusätzlich zu den automatisch generierten RI-Regeln
programmiert werden muss.
Rechnungsseitig hat das Anlegen eines neuen Kunden keine Auswirkungen, da auch
Kunden ohne Rechnungen zugelassen sind.
Für die Insert Regel gibt es nur die Alternativen RESTRICT und IGNORE. Wer Wert auf eine
in sich stimmende Datenbank legt, sollte IGNORE als RI-Regel natürlich
vermeiden.
2.
Update: C = CASCADE
Die Änderung des Primärschlüssels im Adressdatensatz muss an den jeweils
verknüpften Kundendatensatz weitergegeben werden. Die RI-Regel für Updates von
natürlichen Primärschlüsseln ist eigentlich immer CASCADE, das heißt,
Weitergeben dieser Änderung an die verknüpften Datensätze. Ein solcher Update
kann natürlich einige Zeit in Anspruch nehmen, wenn viele verknüpfte Sätze
vorhanden sind. Deshalb gibt es auch die Möglichkeit, durch RESTRICT eine
Änderung des Primärschlüssels zu verhindern, falls verknüpfte Datensätze
vorhanden sind.
Bei Verwendung von künstlichen Schlüsseln (Surrogat Keys) ist RESTRICT generell zu empfehlen, da eine
solche Änderung nur ungewollt sein kann.
3.
DELETE: C = CASCADE
Wenn ein Kundensatz gelöscht wird, müssen auch alle Rechnungssätze des Kunden
gelöscht werden. Diese RI-Regel entscheidet also nicht darüber, ob ein Kunde
gelöscht werden darf. Sie besagt lediglich, was zur Aufrechterhaltung der
referentiellen Integrität passieren muss, wenn ein Kunde gelöscht wird.
Alternativen bei der RI-Regel für Delete sind RESTRICT, NULLIFY und DEFAULT. RESTRICT
verhindert dann das Löschen, wenn verknüpfte Daten vorliegen, während NULLIFY
den Fremdschlüssel im verknüpften Datensatz auf .NULL. setzt. Etwas ähnliches macht
auch die DEFAULT Regel. Nur wird hier der Fremdschlüssel nicht auf .NULL.
gesetzt, sondern auf den definierten Default-Wert. Dieser
Default-Fremdschlüssel müsste dann auf einen Default-Datensatz verweisen, wobei
wir sicherstellen müssen, dass der Default-Datensatz selbst nicht gelöscht
wird.
RI und Business-Rules
Da der RI-Code nicht zwischen
offenen und bezahlten Rechnungen unterscheiden kann, lässt sich die
Geschäftsregel „kein Kunde mit offenen Rechnungen darf gelöscht werden“, nicht
als RI-Regel darstellen. Anders wäre das, wenn die offenen Rechnungen in einer
getrennten Tabelle geführt würden:
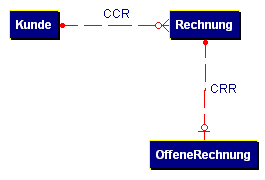
Beim Löschen eines Kunden würde der in der Datenbank hinterlegte RI-Code nun versuchen,
auch alle Rechnungen dieses Kunden zu löschen. Wenn er dabei auf eine Rechnung
stößt, die noch in der Tabelle der offenen Rechnungen abgelegt ist, wird das
Löschen der Rechnung durch die RI-Delete Regel RESTRICT verhindert. Dadurch wird auch das
Löschen des Kunden verhindert. Ein solcher, mehrstufiger RI-Code muss also in eine
Transaktion gekleidet sein, damit die gesamte Aktion rückgängig gemacht werden
kann. In der Praxis wird man die offenen Rechnungen jedoch selten in einer
gesonderten Tabelle vermerken. Eine offene Rechnung ist im allgemeinen ja keine
eigenständige Entität sondern nur ein spezieller Zustand der Entität
„Rechnung“. Wenn man eine solche Struktur aus programm- oder datentechnischen
Gründen vermeiden will, muss man die Geschäftsregel „Kunden mit offenen
Rechnungen dürfen nicht gelöscht werden“ gesondert programmieren und mit den
RI-Regeln verknüpfen.
Regeln verknüpfen
Wie macht man das? Die
RI-Regeln werden in VFP von den Triggern aufgerufen. Die aufzurufenden
Prozeduren können im Tabellen-Designer auf der dritten Page angegeben werden.
Die aufgerufenen Prozeduren müssen .T. oder .F. zurückliefern. Abhängig von
dieser Rückgabe wird der Befehl, der den Trigger ausgelöst hat (z.B. ein INSERT
INTO <Tabelle> VALUES (<Wert1>,<Wert2>,...) ), durchgeführt oder nicht. Da auch dieser Aufruf
der Trigger-Prozeduren nichts anderes als Ausdrücke sind, die VFP ganz normal
auswertet, kann man in einem solchen Ausdruck auch mehrere Prozeduren aufrufen
und diese mit AND oder
OR verknüpfen.
Nehmen wir einmal an, wir
haben in den Stored Procedures eine Funktion namens BR_Delete_Kunde() abgelegt,
also eine Business-Rule, die abprüft, ob der aktuelle Kunde gelöscht werden darf. Diese Funktion
gibt .F. zurück, wenn der Kunde nicht gelöscht werden darf, weil zum Beispiel
noch offene Rechnungen vorliegen. Die Verknüpfung mit dem RI Delete Code müsste dann
durch
BR_Delete_Kunde()
AND __ri_delete_kunde()
erfolgen. Zunächst wird
also die Geschäftsregel überprüft. Wenn die bereits .FALSE. zurückliefert, ist
für VFP die Sache erledigt. Der gesamte Ausdruck liefert dann .F. zurück, die
zweite Prozedur muss nicht mehr aufgerufen werden, um das zu entscheiden. Also
ruft VFP sie auch nicht auf. Der Kunde wird nicht gelöscht und der RI Code
nicht durchgeführt. (Merke: der RI Code wird durchgeführt BEVOR die eigentliche
Aktion ausgeführt wird, die ihn getriggert hat!) Wenn die Geschäftsregel .T.
zurückliefert, muss VFP auch die RI Prozedur aufrufen, um den gesamten Ausdruck
zu evaluieren. Wenn auch diese .T. zurückliefert, wird der Kunde gelöscht.
Folgeaktionen durchführen
Weiter oben haben wir
schon mal über das Ergänzen von Daten bei der Satzvalidierung gesprochen und
festgestellt, dass diese nur für das Ergänzen von Daten im aktuellen Satz
geeignet ist. Über die Triggerausdrücke können wir jetzt aber auch Funktionen
aufrufen, die Folgeaktionen durchführen. Da diese Folgeaktionen immer davon
abhängen, ob die Hauptaktion selbst durchgeführt werden kann, müssen sie nach
dem RI Code aufgerufen werden:
BR_Delete_Kunde() AND __ri_delete_kunde() AND
FO_Delete_Kunde()
Das Prinzip ist das
gleiche. Die Folgeaktion FO_Delete_Kunde() wird nur dann aufgerufen, wenn die
beiden vorausgehenden Aufrufe .T. zurück liefern. Aber Achtung! Die Folgeaktion
kann zwar ebenfalls .F. zurück liefern, um die Hauptaktion zu verhindern. Der
RI Code ist dann aber bereits ausgeführt und hat vielleicht schon verknüpfte
Sätze gelöscht oder eine Wertänderung weitergegeben.
Transaktionen
Der RI Code des VFP
Assistenten und auch der von xCase generierte RI Code startet für seinen
Bereich eine eigene Transaktion. RI Code und Folgeaktionen müssen aber in eine
gemeinsame Transaktion eingekleidet werden. Dazu brauchen wir also Start und
Ende Prozeduren, die in den Triggerausdruck verknüpft werden können. Die
Abfolge der Regeln wird dann über geschachtelte IIFs gesteuert. Das Schema des
gesamten Triggerausdrucks sieht dann so aus:
_bt AND IIF(_br,IIF(_ri,IIF(_fo,_et,_rb),_rb),_rb)
Die Abkürzungen stehen
dabei für folgende Stored Procedures:
_bt führt
BEGIN TRANSACTION aus, falls noch 2 Transaktionslevel übrig sind, gibt in dem
Fall .T. zurück, sonst .F.
_br Abprüfung der Geschäftsregel
_ri RI Code zur Sicherstellung der
referentiellen Integrität
_fo Folgeaktionen
_et führt END TRANSACTION aus, gibt .T.
zurück
_rb führt ROLLBACK aus, gibt .F. zurück
RI und Integrität der Werte
Zurück zu den RI-Regeln.
Betrachten wir zunächst noch einmal die Frage, welche Regeln für die Relation ![]() gelten, speziell beim Löschen einer Adresse.
Sollte dann der zugehörige Kundensatz ebenfalls gelöscht werden? Wenn man nur
die referentielle Integrität seiner Daten sicherstellen will, hat man auch andere Alternativen. So könnte
die NULLIFY Regel oder die DEFAULT Regel eingesetzt werden.
gelten, speziell beim Löschen einer Adresse.
Sollte dann der zugehörige Kundensatz ebenfalls gelöscht werden? Wenn man nur
die referentielle Integrität seiner Daten sicherstellen will, hat man auch andere Alternativen. So könnte
die NULLIFY Regel oder die DEFAULT Regel eingesetzt werden.
Für die wertmäßige
Integrität der Daten bringen aber beide Regeln nicht viel. Die Kundendaten
wären ohne die gelöschte Adresse in jedem Fall unvollständig.
Lassen Sie uns noch einen
anderen Fall betrachten, bei dem die Integrität der Werte eine Rolle spielt.
![]() In diesem Beispiel enthält die Rechnung
einen Verweis auf die Währung, in der sie erstellt wurde. Eine Währung darf
nicht gelöscht werden, solange sie noch einer Rechnung zugeordnet ist, da sonst
alle Beträge der Rechnung sinnlos würden.
In diesem Beispiel enthält die Rechnung
einen Verweis auf die Währung, in der sie erstellt wurde. Eine Währung darf
nicht gelöscht werden, solange sie noch einer Rechnung zugeordnet ist, da sonst
alle Beträge der Rechnung sinnlos würden.
Echte und unechte Parent-Child
Beziehungen
Warum ist die
Alternative, nämlich alle Rechnungen in dieser Währung ebenfalls zu löschen,
wenn die Währung gelöscht wird, unsinnig? Bei der Beziehung von Kunden zu
Rechnungen haben wir doch genau dies gefordert. Warum also nicht auch bei der
Beziehung Währungen zu Rechnungen? Beides sind doch sogenannte Parent-Child
Beziehungen? Offensichtlich gibt es aber „echte“ und „unechte“ Parent-Child
Beziehungen. In einer echten Parent-Child Beziehung ist die Parent-Entität
Besitzer, Auslöser oder Ursprung der zugeordneten Child-Entitäten. In einer
unechten Parent-Child Beziehung ist die Parent-Entität lediglich eine
gesonderte, detaillierte Beschreibung eines Attributs der Child-Entität.
Für echte Parent-Child
Beziehungen lautet die Delete RI-Regel im allgemeinen CASCADE, für unechte
Parent-Child Beziehungen dagegen RESTRICT.
.NULL. Unterstützung in der Insert Regel
Gerade bei unechten
Parent-Child Beziehungen kommt es häufig vor, dass die Angabe eines gültigen Parent Satzes zu einem
Attribut des Childs eigentlich gar nicht so zwingend erforderlich ist. Denken Sie an Kunden,
denen eine Zahlungsbedingung zugeordnet wird. Es wäre reichlich unflexibel,
wenn das Speichern eines neuen Kunden nicht möglich wäre, nur weil die
Zahlungsbedingung nicht angegeben wurde. Wenn dem Kunden später die erste
Rechnung gestellt werden soll, kann das Programm immer noch darauf hinweisen,
dass die Zahlungsbedingung fehlt. Es wäre also schön, wenn der Fremdschlüssel für
die Zahlungsbedingung leer bleiben könnte. Das lässt aber der RI Code nicht zu,
da eine Zahlungsbedingung mit einem leeren Primärschlüssel nicht existiert. (Es
sei denn, wir hätten explizit eine solche angelegt.) Eigentlich ist ja „leer“
auch nicht der richtige Wert. Besser wäre .NULL. für „unbekannt“.
Die Insert Regel RESTRICT
sollte also nur durchgesetzt werden für Fremdschlüssel, die nicht .NULL. sind.
Das ist bei dem vom VFP Assistenten generierten RI Code nicht möglich.
Schlimmer noch: Wenn ein Fremdschlüssel einmal .NULL. ist, kann er anschließend
jeden beliebigen Wert annehmen, weil der RI Code wegen fehlender .NULL.
Unterstützung dann falsch reagiert. Auch der von xCase generierte RI Code bot
lange Zeit keine durchgängige .NULL. Unterstützung. Fremdschlüssel konnten zwar
von der Delete Regel auf .NULL. gesetzt werden. Ein Insert mit .NULL. Fremdschlüsseln funktionierte jedoch
nicht, sondern lief auf einen Fehler. Ab der xCase Version 5 ist dies aber
behoben.
Zusammenfassung:
Mit den Feld- und Satzvalidierungen
und den Triggern in VFP kann man eine Menge von Regeln bereits in der Datenbank
verankern – Geschäftsregeln und RI-Regeln sollten dabei gedanklich
unterschieden werden. Benutzen Sie die Möglichkeiten der VFP Datenbank, Ihre
Daten sicher und stimmig zu speichern. Ich hoffe, dieser Artikel kann Ihnen
dabei helfen.